
- What is Financial Modeling?
- What is Financial Modeling Used For?
- What are the Financial Modeling Best Practices?
- What are the Different Types of Financial Models?
- Reducing Errors in Financial Models with AI
- Financial Modeling Course Excel Template
- What are the Examples of Financial Modeling?
- How to Structure a Financial Model
- What is the Purpose of Financial Modeling?
- How to Format a Financial Model
- Guidelines for Color Coding in Financial Modeling
- How to Make Financial Models Easier to Audit
- What are the Sign Convention Rules in Financial Modeling?
- How to Maintain Consistency in Financial Modeling
- How to Ensure Simplicity in Financial Models (“BASE”)
- How to Manage Date Complexities in Excel
- How to Name Cells and Ranges
- What are Common Mistakes in Financial Modeling?
- One Sheet vs. Multiple Sheet Financial Model: Which is Better?
- Why Group Rows Instead of Hiding Them?
- How to Structure a Financial Model
- Annual vs. Quarterly Model: How to Adjust for Periodicity
- How to Handle Circular References in Financial Modeling
- How to Error-Proof a Financial Model
- Industry Guidelines on Presentability and Design
- How to Integrate Scenario and Sensitivity Analysis
What is Financial Modeling?
Financial Modeling is a tool to understand and perform analysis on an underlying business to guide decision-making, most often built in Excel.
In practice, the most common types of financial models used on the job include the 3-statement model, discounted cash flow (DCF) analysis, comparable company analysis (CCA), merger model (accretion/dilution analysis), and leveraged buyout model (LBO).

- Financial modeling is forecasting the financial performance of a company for various use cases, such as profitability and valuation analyses.
- Financial modeling requires an understanding of the historical financial data of the company, operating drivers, and relevant market data on comparable companies in the same (or adjacent) industry.
- The most common types of financial models include the 3-statement model, trading and transaction comps, DCF model, merger model, and LBO model.
- The objective of financial modeling is to analyze the underlying company to determine the core components of its business model and value drivers.
What is Financial Modeling Used For?
Financial modeling is a tool to analyze a particular company’s historical performance and relevant market data on comparable companies operating in the same (or adjacent) industry to project its financial performance.
By forecasting the operating and financial performance of a company (or project), financial models are practical for various use-cases and guide decision-making, such as in the context of performing a valuation or capital budgeting analysis.
The following list contains the top ten most common types of financial models:
- 3-Statement Model (Income Statement, Cash Flow Statement, Balance Sheet)
- Discounted Cash Flow Analysis (DCF Model)
- Comparable Company Analysis (Trading Comps Model)
- Precedent Transactions Analysis (Transaction Comps Model)
- Merger Model (M&A Accretion/Dilution)
- Leveraged Buyout (LBO) Model
- Initial Public Offering (IPO) Model
- Sum-of-the-Parts Model (SOTP Valuation)
- Capital Budgeting Model (Capital Investment Model)
- Lender Model (Credit Risk Analysis)
What are the Financial Modeling Best Practices?
Financial modeling best practices refer to industry-standard modeling conventions and tips to adhere to when building models in Excel.
Following these general guidelines and industry best practices ensures that the financial models built on the job are intuitive, error-proof, and structurally sound.
Like many computer programmers, people who build financial models can get opinionated about the “right way” to do it.
In fact, there is surprisingly little consistency across Wall Street around the structure of financial models.
One reason is that financial models can vary widely in purpose, which, along with the context of the analysis, determines the required level of granularity and structure of the model.
For example, if your task was to build a discounted cash flow (DCF) model to be used in a preliminary pitch book as a valuation for one of 5 potential acquisition targets, it would likely be a waste of time to build a highly complex and feature-rich model.
The time required to build a super complex DCF model isn’t justified, given the purpose of the financial model (and the context of the analysis).
On the other hand, a leveraged finance model used to make thousands of loan approval decisions for various loan types under various scenarios requires a lot of complexity.
What are the Different Types of Financial Models?
The most common types of financial models include the following:
| Type of Financial Model | Description |
|---|---|
| 3-Statement Model |
|
| Discounted Cash Flow (DCF) Model |
|
| Merger Model (Accretion/Dilution Analysis) |
|
| Leveraged Buyout (LBO) Model |
|
| Comparable Company Analysis (Trading Comps) |
|
| Precedent Transactions Model (Transaction Comps) |
|
| Restructuring Model |
|
| Capital Investment Model |
|
| Lender Credit Model |
|
In particular, the core 3-statement financial model is designed to better grasp the operating drivers of a given company and its business model.
Creating a robust projection model requires analyzing a company’s historical performance and the relevant industry trends (and developments) to create a defensible 3-statement forecast, which underpins most valuation models (e.g. DCF analysis), strategic planning, and capital budgeting analyses.
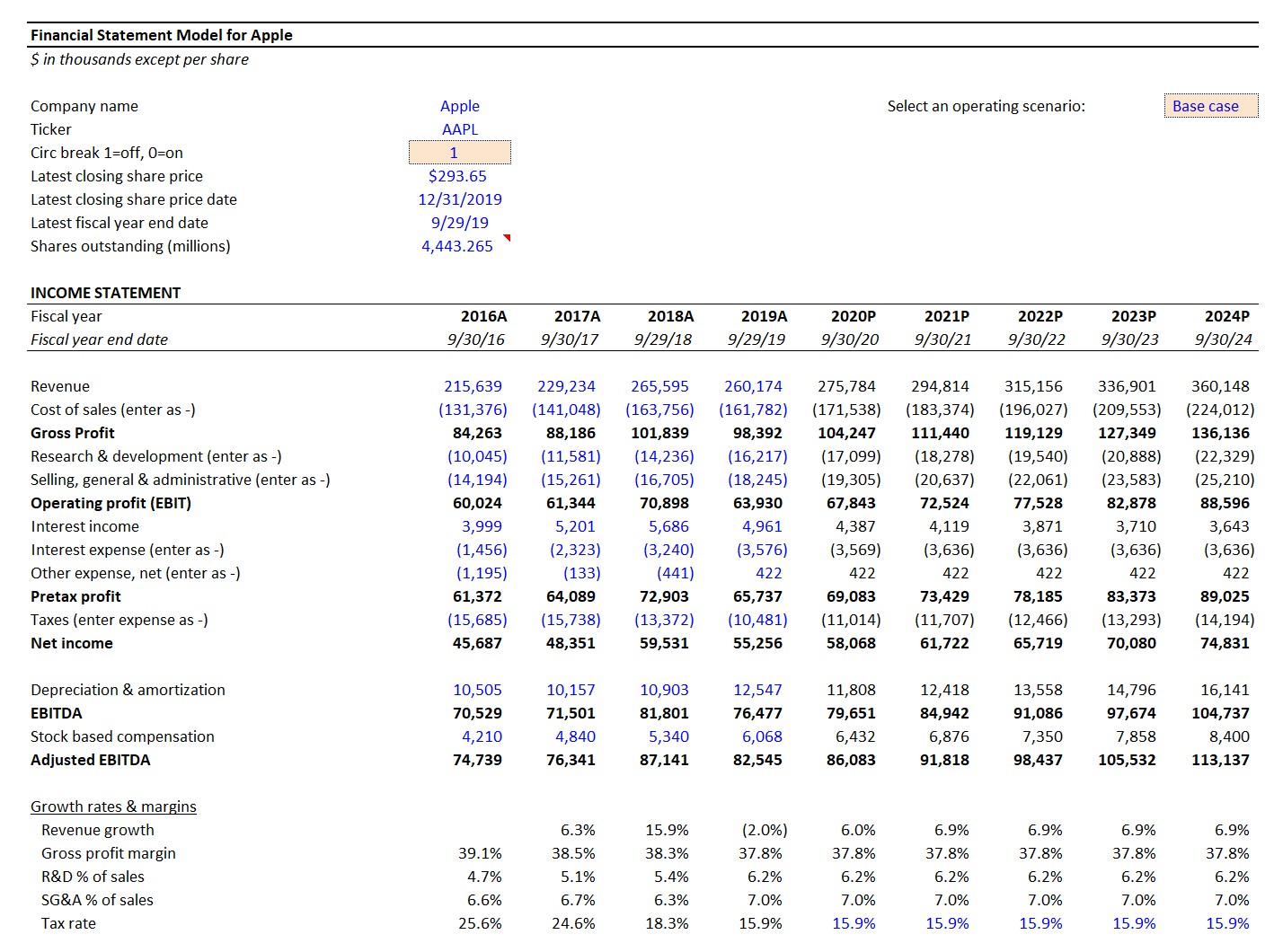
Financial Modeling Example – Apple 3-Statement Model (Source: WSP Financial Modeling Course)

Reducing Errors in Financial Models with AI
Financial modeling is a cornerstone of modern finance, but it remains time-intensive and highly prone to manual error—especially in traditional Excel-based workflows. Artificial intelligence changes that equation by automating repetitive inputs, cross-checking logic across model components, and enabling real-time scenario analysis. The AI for Business & Finance Certificate Program—built by Wall Street Prep in collaboration with Columbia Business School Executive Education—teaches professionals how to implement intelligent model automation and AI-assisted scenario planning to dramatically improve modeling speed, accuracy, and insight generation.
Financial Modeling Course Excel Template
Before we delve into the financial modeling best practices and conventions – are you interested in learning how to build a basic 3-statement model in Excel?
If so, fill out the form below to access our free introductory financial modeling course, including the Excel template that goes along with the tutorial.
What are the Examples of Financial Modeling?
Understanding the purpose of the model is key to determining its optimal structure. There are two primary determinants of a model’s ideal structure:
- Granularity
- Flexibility
Let’s consider the following 5 common types of financial models built in corporate finance.
| Financial Model | Purpose | Granularity | Flexibility |
|---|---|---|---|
| One Page DCF Model |
|
|
|
| Fully Integrated DCF Model |
|
|
|
| Comps Model |
|
|
|
| Restructuring Model (RX) |
|
|
|
| Leveraged Finance Model (LevFin) |
|
|
|
How to Structure a Financial Model
Component 1. Granularity in Financial Modeling
One critical determinant of a financial model’s structure is the concept of granularity.
Granularity refers to how detailed a model needs to be. For example, imagine you are tasked with performing an LBO analysis for Disney.
If the purpose is to provide a back-of-the-envelope floor valuation range to be used in a preliminary pitch book, it might be appropriate to perform a “high-level” LBO analysis, using consolidated data and making very simple assumptions for financing.
If your model is a key decision-making tool for financing requirements in a potential recapitalization of Disney, a far higher degree of accuracy is crucial. The differences in these two examples might involve things like:
- Forecasting revenue and cost of goods segment by segment, and using price-per-unit and #-units-sold drivers instead of aggregate forecasts
- Forecasting financials across different business units, as opposed to looking only at consolidated financials
- Analyzing assets and liabilities in more detail (i.e. leases, pensions, PP&E, etc.)
- Breaking out financing into various tranches with more realistic pricing
- Looking at quarterly or monthly results instead of annual results
Practically speaking, the more granular a model, the longer and more difficult it will be to understand. In addition, the likelihood of errors increases exponentially by having more data.
Concerning the importance of abiding by a consistent structure of a financial model — from the layout of the worksheets to the layout of individual sections, formulas, rows, and columns — the matter is particularly critical for in-depth, granular models.
In addition, integrating formal error and “integrity” checks can mitigate the risk of modeling errors.
Component 2. Flexibility in Financial Modeling
The other main determinant for how to structure a financial model is its required flexibility. A model’s flexibility stems from how often it will be used, by how many users, and for how many different uses. A model designed for a specific transaction or for a particular company requires far less flexibility than one designed for heavy reuse (often called a template).
As you can imagine, a template must be far more flexible than a company-specific or “transaction-specific model”. For example, say you are tasked with building a merger model.
If the purpose of the model is to analyze the potential acquisition of Disney by Apple, you would build in far less functionality than if its purpose was to build a merger model that could handle any two companies.
Specifically, a merger model template might require the following items that are not required in the deal-specific model:
- Adjustments to the Acquirer’s Currency
- Dynamic Calendarization (Set Target’s Financials to Acquirer’s Fiscal Year)
- Insertion of Placeholders (Income Statement, Balance Sheet, and Cash Flow Statement)
- Net operating loss analysis (neither Disney or Apple have NOLs)
The placeholders are for the line items that do not appear on Disney or Apple financials
Put together, granularity and flexibility largely determine the structural requirements in financial modeling.
Structural requirements for models with low granularity and a limited user base are quite low.
There is a trade-off to building a highly structured model per usual, which boils down to time.
In short, simply don’t if you don’t need to build in bells and whistles
But as you add granularity and flexibility into the model, structure and error-proofing become increasingly critical.

The table below shows the granularity and flexibility levels of common investment banking models.
| High Flexibility | Low Flexibility | |
|---|---|---|
| High Granularity |
|
|
| Low Granularity |
|
|
What is the Purpose of Financial Modeling?
Before building a financial model, the first step must be to understand the purpose of the analysis and end-goal.
A financial model is a tool designed to aid decision-making, irrespective of its granularity and flexibility.
Therefore, a proper financial model must have a presented output and conclusion, which should be intuitive and easy to understand.
For instance, if an investment banking analyst submits a valuation model to their direct supervisor, or an associate, the process of auditing the model should be relatively easy, assuming the model was built properly and abides by the standard modeling best practices and industry conventions.
Otherwise, the associate is likely to be frustrated because auditing the model is time-consuming and the “flow” of the model is difficult to comprehend.
While constructing a financial model, constantly remind yourself that another person will soon review your work.
Since virtually all financial models will help decision-making within various assumptions and forecasts, an effective model will allow users to easily modify and sensitize various scenarios and present information in various ways.
How to Format a Financial Model
Thus far, we’ve established a simple framework for structuring models, so it is now time to discuss specific features of model architecture, error proofing, flexibility, and presentation, where we’ll lay out the key elements of an effectively structured model.
In particular, these best practices and industry conventions will go a long way to improving the transparency of the model.
As a financial model becomes more complex – due to higher granularity and flexibility – the model naturally becomes less transparent.
The financial modeling best practices and practical tips described in the next sections will help fix this, starting with the following guidelines around formatting financial models.
Guidelines for Color Coding in Financial Modeling
Just about everyone agrees that color-coding cells based on whether the cell contains a hard-coded number or a formula are critical. Without color coding, it is extremely difficult to visually distinguish between cells that should be modified and cells that should not (i.e. formulas).
A properly built financial model will further distinguish between formulas that link to other worksheets and workbooks, as well as cells that link to financial data services, like Capital IQ and FactSet.
While different investment banks have different house styles, blue is typically used to color inputs, and black is used for formulas (or calculations).
The table below shows our recommended color coding scheme.
| Cell Type | Excel Formula | Color Scheme |
|---|---|---|
| Hard-Coded Numbers (Inputs) | =1234 | Blue |
| Formulas (Calculations) | =A1*A2 | Black |
| Links to Other Worksheets | =Sheet2!A1 | Green |
| Links to Other Files | =[Book2]Sheet1!$A$1 | Red |
| Links to Data Providers (e.g. CIQ, FactSet) | =CIQ(IQ_TOTAL_REV) | Dark Red |
While everyone agrees that color coding is important, keeping up with it can be a pain in native Excel. It’s not easy to format cells based on whether they are inputs or formulas, but it can be done. One option is to use Excel’s “Go To Special”.
Alternatively, color coding is dramatically simplified with a third-party Excel add-in like Capital IQ or Factset.
These tools allow you to “auto-color” an entire worksheet in one click.
How to Make Financial Models Easier to Audit
Inserting comments (Shortcut “Shift F2”) in cells is critical for footnoting sources and adding clarity to data in a model.

For example, a cell with an assumption of revenue growth from an equity research report should include a comment regarding the research report.
So how much commenting do you need?
Always err on the side of over-commenting.
No managing director (MD) at an investment bank will complain that a financial model contains too many comments.
Conversely, a financial model with inputs and calculations, where the rationale is not straightforward to understand, is prone to criticism.
Additionally, if you’re on a conference call and someone asks how you came up with the number in cell AC1238, and you are not sure, you’ll regret not commenting.
What are the Sign Convention Rules in Financial Modeling?
The decision on whether to use positive or negative sign conventions must be made before the model is built.
Models in practice are all over the place on this one. The modeler should choose from and clearly identify one of the following 3 approaches:
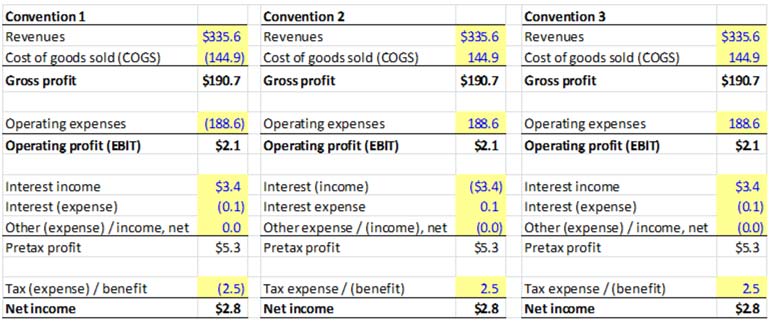
Convention 1. Income = Positive; Expenses = Negative
- Advantage: logical, consistent, makes subtotal calculations less error-prone
- Disadvantage: Doesn’t align with conventions used by public filings, % margin calculations appear negative
Convention 2. Expenses Positive; Non-Operating Income Negative.
- Advantage: Consistent with public filings, % margin calculations appear positive
- Disadvantages: Negative non-operating income is confusing, subtotal calculations are error-prone, proper labeling is critical
Convention 3. Expenses Positive (Except Non-Operating Expenses)
- Advantage: Avoids negative non-operating income presentation; margins evaluate to positive
- Disadvantage: Presentation not internally consistent. Proper labeling is critical.
Our recommendation is Convention 1. The reduced likelihood of error from easier subtotaling alone makes this our clear choice. In addition, one of the most common mistakes in modeling is forgetting to switch the sign from positive to negative, or vice versa when linking data across financial statements. Convention 1, by virtue of being the most visibly transparent approach, makes it easier to track sign-related mistakes.
How to Maintain Consistency in Financial Modeling
Hard-coded numbers (constants) should never be embedded into a cell reference.
The danger here is that you’ll likely forget there is an assumption inside a formula. Inputs must be separated from calculations.

Most investment banking models, like the 3-statement model, rely on historical data to drive forecasts.
Financial data should be presented from left to right. The right of the historical columns are the forecast columns. Hence, the left section font color is blue, while the projection section on the right is black.
While building a financial model in Excel, remember the rule: “One Row, One Calculation”.
The formulas in the forecast columns should be consistent across the row.

How to Ensure Simplicity in Financial Models (“BASE”)
In financial modeling, roll-forward schedules (“BASE” or “Cork-Screw”) refer to a forecasting approach that connects the current period forecast to the prior period.
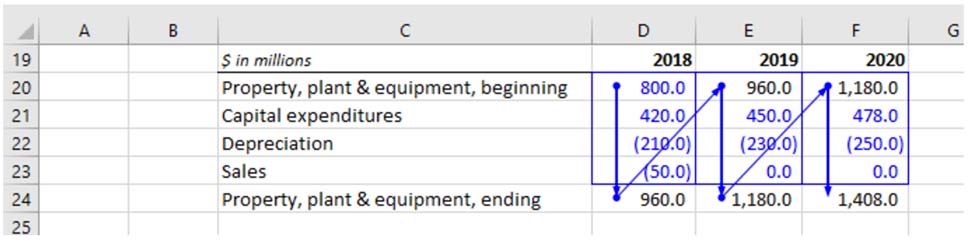
This approach is useful in adding transparency to how schedules are constructed. Maintaining strict adherence to the roll-forward approach improves a user’s ability to audit the model and reduces the likelihood of linking errors.
There is a temptation when working in Excel to create complicated formulas.
While it may feel good to craft a super complex formula, the obvious disadvantage is that no one – including the author after being away from the model for a bit – will understand it.
Because transparency should drive structure, complicated formulas should be avoided at all cost. A complicated formula can often be broken down into multiple cells and simplified. Remember, Microsoft doesn’t charge you extra for using more cells! So take advantage of that. Below are some common traps to avoid:
- Simplify IF statements and avoid nested IFs
- Consider using flags
For instance, “IF” statements in financial models – while intuitive and well understood by most Excel users – can become long and difficult to audit.
There are several excellent alternatives to IF that top-notch modelers frequently use. They include using Boolean logic along with various reference functions, including MAX, MIN, AND, OR, VLOOKUP, HLOOKUP, and OFFSET.
Below is a real-world example of how an IF statement can be simplified. Cell F298 uses any surplus cash generated during the year to pay down the revolver, up until the revolver is fully paid down.
However, if deficits are generated during the year, we want the revolver to grow. While an IF statement accomplishes this, a MIN function does it more elegantly:
Example 1. Revolver Formula Using IF Statement

Example 2. Revolver Formula Using Excel MIN Function

The revolver formula using MIN as an alternative to IF also holds up better when additional complexity is required. Imagine there’s a limit on the annual revolver draw of $50,000. Look at how we have to modify both formulas to accommodate this:
Example 3. Revolver Formula Using IF Statement (Modified)

Example 4. Revolver Formula Using Excel MIN and MAX Function
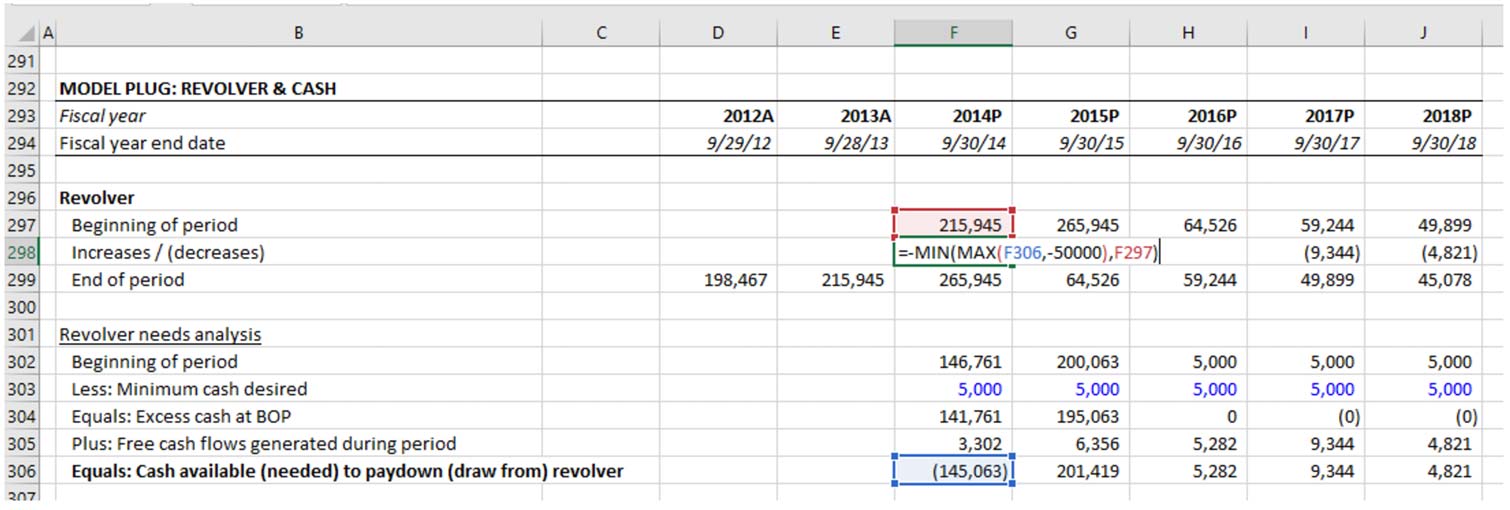
While both formulas are challenging to audit, the formula using IF statements is more difficult to audit and is more vulnerable to getting completely out of hand with additional modifications. It uses nested (or embedded) IF statements, with which our feeble human brains have a hard time once there are more than one or two.
Fortunately, Excel has made this a bit easier in 2016 with the introduction of the IFS function, but our preference for relying on more elegant functions remains.
How to Manage Date Complexities in Excel
Flags refer to a modeling technique most useful for modeling transitions across phases of a company, project or transaction over time, without violating the “one row/one calculation” consistency rule.
Imagine you’re building a model for a company contemplating bankruptcy. Each phase of the restructuring process has its own distinct borrowing and operating characteristics.
In our example below, the company’s revolver “freezes” once it goes into bankruptcy, and a new type of borrowing (“DIP”) acts as the new revolver until the company emerges from bankruptcy.
Additionally, a new “Exit” facility replaces the DIP. We insert 3 “flags” in rows 8-10 to output “TRUE/FALSE” based on the phase we’re in. This enables us to build very simple, consistent formulas for each revolver, without having to embed IF statements into each calculation.
In cell F16, the formula is =F13*F8. Whenever you apply an operator (like multiplication) on a TRUE, the TRUE is treated like a “1” while a FALSE is treated like a “0.” This means the pre-bankruptcy revolver is the de facto revolver when the pre-bankruptcy flag evaluates to TRUE and becomes 0 once the flag evaluates to FALSE (starting in column I in our example below).
The main benefit is that with the use of just an extra 3 rows, we’ve avoided having to insert any sort of conditional tests within the calculations. The same applies to the formulas in rows 20 and 204 — the flags have prevented a lot of extra code.

How to Name Cells and Ranges
Another way many modelers reduce formula complexity is by using names and named ranges.
That said, we strongly caution against using names and named ranges.
Why? As you’re probably beginning to sense, there is always some sort of trade-off with Excel. In the case of names, the trade-off is that when you name a cell, you no longer know exactly where it is without going to the name manager.
In addition, unless you are proactively deleting names (you aren’t), Excel will retain these names even when you delete the named cell. The result is that a file you’re using today to build a DCF contains dozens of phantom names from previous versions of the model, leading to warning messages and confusion.
What are Common Mistakes in Financial Modeling?
Do Not Calculate on the Balance Sheet – Link from Supporting Schedules Instead
In investment banking, your financial models frequently involve financial statements. Ideally, your calculations are done in schedules separate from the output you’re working towards.
For example, you shouldn’t perform any direct calculations on the model’s balance sheet.
Instead, balance sheet forecasts should be determined in separate schedules and linked to the balance sheet, as illustrated below.
This consistency enhances transparency in the model, making it easier to audit.

Never Re-Enter the Same Input in Different Cells
For example, if you’ve inputted a company name in the first worksheet of the model, reference that worksheet name — don’t re-type it into the other worksheets.
The same goes for years and dates entered into a column header or discount rate assumptions used in various places in the model.
A more subtle example of this is hard coding subtotals or EPS when you can calculate it. In other words, calculate whenever possible.

Always Link Directly to a Source Cell – Easier to Audit “Daisy Chained” Data

The one major exception is when “straight-lining” base period assumptions.
For this, go ahead and daisy chain. The reason is that straight-lining base period assumptions are an implicit assumption, that can change, making it possible for certain years in the forecast to ultimately end up with different assumptions than other years.
Avoid Formulas Containing References to Multiple Worksheets
Compare the two images below – it is far more difficult to audit the formula in the first image because you’ll need to bounce around to different worksheets to view the precedent cells.
Therefore, bring the data from other worksheets into the active worksheet where the calculation is made whenever possible.

Link Assumptions into Standalone Cells in the Calculation and Output Sheets
If you’re working with larger models and have assumptions that need to be referenced from a separate worksheet, consider linking assumptions directly into the worksheet where you’re using them, and color code them as a distinct worksheet reference link.
In other words, don’t have an input reference embedded into a calculation (i.e. =D13*input!C7).
Instead, use a clean reference =input!C7 and a separate cell for the calculation. While this creates a redundant cell reference, it preserves the visual auditability of the model tab and reduces the likelihood of error.
Avoid Linking External Files
Excel allows you to link to other Excel files, but others might not have access to the linked-to files, or these files may get inadvertently moved.
Therefore, avoid linking to other files whenever possible.
If linking to other files is necessary, be vigilant about color-coding all cell references to other files.
One Sheet vs. Multiple Sheet Financial Model: Which is Better?
In short, a financial model presented on a single long sheet is preferable over many short sheets.
A long worksheet means a lot of scrolling and less visual compartmentalizing of sections.
On the other hand, multiple worksheets significantly increase the likelihood of linking errors.
There’s no hard and fast rule about this, but the general bias should be toward a longer sheet over multiple, shorter worksheets.
The dangers of mis-linking across worksheets are quite real and hard to mitigate, while the issues of cumbersome scrolling and lack of compartmentalization associated with long worksheets can be drastically mitigated with Excel’s split screen functionality, clear headers, and links from a cover sheet or table of contents.
Why Group Rows Instead of Hiding Them?
As a general financial modeling best practice, do not hide rows. Instead, group the rows (and do it sparingly).
A model often has rows with data and calculations that you do not want to show when the model is printed or when you paste the data into a presentation. In this situation, it’s often tempting to hide rows and columns for a “cleaner” presentation of results.
The danger is that when the model is passed around, it is very easy to miss (and potentially paste over) the hidden data.

How to Structure a Financial Model
In short, group the inputs (i.e. the assumptions) that drive the financial model together in one section.
Nearly every financial modeling expert recommends a standard that isolates all of the model’s hard-coded assumptions (things like revenue growth, WACC, operating margin, interest rates, etc…) in one clearly defined section of a model — typically on a dedicated tab called “Inputs”.
These should never be commingled with the model’s calculations (i.e. balance sheet schedules, financial statements) or outputs (i.e. credit and financial ratios, charts and summary tables).
In other words, think of a model comprised of three clearly identified and physically separated components:
The advantages of using one sheet are as follows.
- Consistent, reliable architecture: Once a model is built, the user has only one place to go to change any assumptions. This creates a consistent distinction between areas in the model that the user works in vs. areas the computer works in.
- Error mitigation: Storing all assumptions in one place makes it far less likely that you’ll forget to remove old assumptions from a prior analysis and inadvertently bring them into a new analysis.
Yet despite these advantages, this practice has never been widely adopted in investment banking.
One reason is simply poor practice. Some models would benefit from an input/calculation/output separation but are often built with no forethought given to structure. Imagine building a house without any pre-planning.
Sure, you’ll avoid the pain of all that planning, but you’ll encounter unforeseen problems and end up redoing work or adding complexity by working around what’s already been done. This problem is rampant in investment banking models.
Another reason is that many investment banking models are simply not granular enough to merit the additional audit trail and legwork.
The analyses bankers perform are often broader than in-depth, at least initially.
For example, a pitch book might present a valuation using 4 different valuation models, but none of them will be overly granular.
Common investment banking analyses like accretion dilution models, LBO models, operating models, and DCF models usually don’t delve into detail beyond the limits of public filings and basic forecasting. In this case, moving back and forth from input to calculation to output tabs is unnecessarily cumbersome.
As long as you’re diligent about color coding, placing assumptions on the same sheet and right below calculations is preferable in smaller models, because your assumptions are visually right next to the output, making it easy to see what’s driving what.
The other consideration is the number of users of a model. The advantages of the “inputs together” approach grow with the number of intended users of a model. When you have many users, your model will inevitably be used by people with a wide range of modeling proficiency.
In this case, a consistent and reliable structure that prevents users from getting into the guts of the model will reduce error. In addition, it will also reduce the time a user spends in the model.
A user can simply locate the area for inputs, fill them in, and the model (in theory) will work.
That said, despite attempts by IB teams to standardize models, many investment banking models are essentially “one-offs” that get materially modified for each new use.
Apart from comps models, which are becoming templates, most models are used primarily by their original authors (usually an analyst and associates) who understand the model well.
The bottom line on keeping inputs all together: Unfortunately, there’s no established benchmark for when it makes sense to separate assumptions. The ideal approach depends on the scope and goal of the model.
For a simple 1-page discounted cash flow analysis not intended for frequent reuse, it is preferable to embed inputs throughout the page.
However, for a large fully integrated LBO model with many debt tranches to be used as a group-wide template, the benefits of keeping all inputs together will outweigh the costs.
No Spacer Columns Between Data

Elevator Jumps
In long worksheets, dedicating the leftmost column to placing an “x” or another character at the start of schedules will make it easy to quickly navigate from section to section.

Annual vs. Quarterly Model: How to Adjust for Periodicity
Most investment banking models are either quarterly or annual. For example, a U.S. equity research earnings model will always be a quarterly model because one of its key purposes is to forecast upcoming earnings, which are reported by firms quarterly.
Similarly, a restructuring model is usually a quarterly model (or even a monthly or weekly model) because a key purpose of this model is to understand the cash flow impact of operational and financing changes over the next 1-2 years.
On the other hand, a DCF valuation is a long-term analysis, with at least 4-5 years of explicit forecasts required. In this case, an annual model is appropriate.
There are also models for which both quarterly and annual periods are useful. For example, a merger model usually needs a quarterly period, because a key goal is to understand the impact of the acquisition on the acquirer’s financial statements over the next 2 years.
However, attaching a DCF valuation to the combined merged companies may also be desirable. In this case, a possible solution is to roll up the quarters into an annual model and extend those annual forecasts further out.
When determining a model’s periodicity, remember the following:
- The model must be set up with the smallest unit of time desired, with longer periods aggregated (“rolled up”) from those shorter periods. If you’re building an integrated financial statement model in which you want quarterly and annual data, forecast the quarterly data first.
- Keep the quarterly and annual data in separate worksheets. It is easier to audit what’s going on when periods aren’t commingled. Additionally, commingling quarterly and annual data in one worksheet will either A) force you to violate the one row/one formula consistency best practice, or B) you will have to jump through some crazy hoops to maintain the consistency.

Everything You Need To Master Financial Modeling
Enroll in The Premium Package: Learn Financial Statement Modeling, DCF, M&A, LBO and Comps. The same training program used at top investment banks.
Enroll TodayHow to Handle Circular References in Financial Modeling
Circularity refers to a cell referring to itself (directly or indirectly). Usually, this is an unintentional mistake. In the simple example below, the user accidentally included the sum total (D5) in the sum formula. Notice how Excel becomes confused:

But sometimes a circularity is intentional.
For example, if a model calculates a company’s interest expense based on a cell that calculates the company’s revolving debt balance, but that revolving debt balance is itself determined by (among other things) the company’s expenses (including interest expense), then we have a circularity.
The logic of such a calculation is sound: A company’s borrowing needs should take into account the interest expense. As such, many investment banking models contain intentional circularities like these.

Since unintentional circularity is a mistake to avoid, the usage of intentional circularity in financial models is controversial.
The problem with intentional circularity is that a special setting must be selected within ‘Excel Options’ to prevent Excel from misbehaving when a circularity exists:
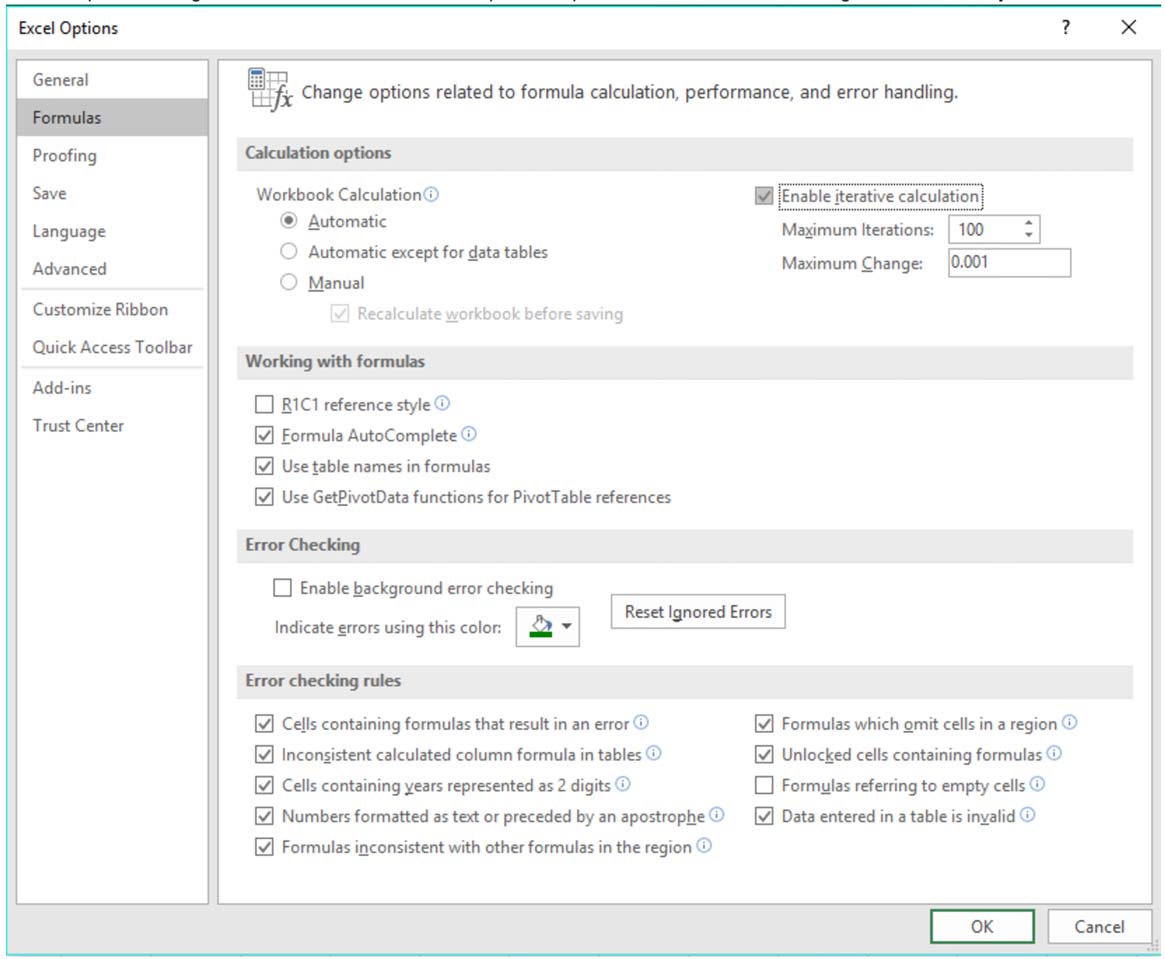
Even with these settings selected, Excel can become unstable when handling circularity and often leads to a model “blowing up” (i.e. the model short-circuits and populates the spreadsheet with errors), requiring manual intervention to zero out the cells containing the source of circularity:

While the underlying logic for wanting to incorporate a circularity into a model may be valid, circularity problems can lead to minutes, if not hours, of wasted auditing time trying to locate the source(s) of circularity to zero them out.
There are several things modelers can do to better cope with circularity, most notably the creation of a simple circuit breaker, which creates a central place in the model that “resets” any cell containing a circularity, or wrapping an error-trap formula (IFERROR Excel Function) around the formula that is the source of the circularity.
IFERROR Error-Trap
When building an intentional circularity, you MUST build a circuit breaker and identify all the circularities in your model.
In our simple example, we placed a circuit breaker in D17 and altered the formula in D8 so the circularity is zeroed out when the user switches the breaker to “ON”.
Approach 1. Adding a Circuit Breaker Toggle

An alternative approach is to simply wrap an IFERROR function around the source of the circularity.
When the model short circuits, the IFERROR function evaluates to the FALSE condition and populates the model with 0s automatically.
The primary downside to this approach is that it makes finding unintentional circularities harder. That’s because you can never explicitly turn the breaker on or off – the IFERROR does it automatically.
That said, as long as all circs are handled with an IFERROR function, the model will never blow up.
Approach 2. Add an Error Trap Using the IFERROR Function

Bottom Line: To Circ or Not to Circ?
Despite the circuit breaker and error trap solutions, many believe it is preferable to simply outlaw all circularity from financial models.
For example, the way to avoid intentional circularities in the example above is to calculate interest expense using the beginning debt balance.
For quarterly and monthly models with minor debt fluctuations, this is desirable, but for an annual model with a large forecasted change in debt, the “fix” can lead to a materially different result.
Therefore, we do not believe in a blanket “ban.” Instead, we provide the following simple guidelines:
Circularities in Excel are only “OK” if all the following conditions are met.
- Intentional Circularity → At the risk of stating the obvious, you must understand exactly why, where, and how the circularity exists. The example above is the most common source of circularity in financial models.
- You have “enable iterative calculation” selected in your Excel settings → This tells Excel the circularity is intentional, and ensures Excel doesn’t throw up an error and populates the entire model with random zeros everywhere.
- You have a circuit breaker or error trap formula → A circuit breaker or error trap formula ensures that if the file gets unstable and #DIV/0!s starts populating the model, there is an easy and clear way to fix it.
- The model will not be shared with Excel novices → Circularities, even with a circuit breaker, can create confusion for Excel users unfamiliar with it. If the model you are building will be shared with clients (or a managing director) who like to get into the model but are generally unfamiliar with Excel, avoid the circularity and save yourself the headache.
Don’t Use Macros (or Limit Usage)
Keep the use of Excel macros to an absolute bare minimum.
Very few people know how macros work, and some users cannot open files that use macros.
Every additional macro is a step closer to making your model a “black box.”
In investment banking, this is never a good thing. The only macros regularly tolerated in banking models are print macros.
How to Error-Proof a Financial Model
Standardize the Format in Financial Modeling
Unlike software specifically designed to perform a particular set of tasks (i.e. real estate investment software, bookkeeping software), Excel is a blank canvas, which makes it easy to perform extremely complicated analyses and quickly develop invaluable tools to help in financial decision-making.
The downside here is that Excel analyses are only as good as the model builder (i.e. “Garbage in = garbage”). Model errors are rampant and have serious consequences.
Let’s break up the most common modeling errors:
- Poor Assumptions: If your assumptions are faulty, the model’s output will be incorrect regardless of how well it is structured.
- Poor Structure: Even if your model’s assumptions are great, mistakes in calculations and structure will lead to incorrect conclusions.
The key to mitigating #1 is to present results with clearly defined ranges of assumptions (scenarios and sensitivities) and make the assumptions clearly defined and transparent.
Standardizing financial models into the Inputs → Calculation → Output format helps others quickly identify and challenge your assumptions, which were addressed in detail in the “Presentation” section above.
The far more pernicious modeling error is #2 because it’s much more difficult to find. As you might imagine, the problem grows exponentially as the model’s granularity increases. Hence, building error checks into your financial model is a critical part of model building.
Built-In Error Checks
The most common error check in a financial model is the balance check – a simple formula to confirm the accounting equation is true (and the balance sheet is in fact “balanced”)
If the balance sheet does not “balance,” a past error or mistake was made that must be promptly identified and fixed, such as a cell reference that links to the wrong cell or an incorrect sign convention.

Anyone who has built an integrated financial statement model knows it is quite easy to make a simple mistake that prevents the model from balancing.
The balance check clearly identifies to the user that a mistake has been made and further investigation is required.
However, there are many other areas of models that are prone to error and thus could merit error checks.
While every model will need its own checks, some of the more common ones include:
- Ensuring sources of funds = uses of funds
- Ensuring quarterly results add up to annual results
- Total forecast depreciation expense does not exceed PP&E
- Debt pay-down does not exceed the outstanding principal
Favor Direct Calculations over “Plugs”
In the next section, we’ll illustrate two common methods that users often use to set up sources & uses of funds tables in financial models.
In both approaches, the user accidentally references intangible assets.
- Approach 1 → In approach 1, the incorrect data is linked to D37. The model notices that sources do not equal uses and throws an error message in D41.
- Approach 2 → The second (and equally common) approach structurally sets D52 equal to D47 and uses D49 as a plug to ensure that sources and uses are always equal. Which approach do you think is preferable? If you guessed the first approach, you are correct.
The problem with the second (“plug”) approach is that because of the mis-linking in D50, the model incorrectly calculates the amount of secured loans required for the transaction, and no error is identified.

Whenever a direct calculation is possible, use it, along with an error check (i.e. “do sources equal uses?”) instead of building plugs.
Aggregate Error Checks into One Area
Place error checks close to where the relevant calculation is taking place, but aggregate all error checks into a central easy-to-see “error dashboard” that clearly shows any errors in the model.
Error Trapping to Reduce Mistakes
Models that require a lot of flexibility (templates) often contain areas that a user may not need now, but will need down the road. This includes extra line items, extra functionality, etc.
This creates room for error because Excel is dealing with blank values. Formulas like IFERROR (and ISERROR), ISNUMBER, ISTEXT, and ISBLANK are all useful functions for trapping errors, especially in templates.
Industry Guidelines on Presentability and Design
Cover Page and Table of Contents (TOC)
When a model is designed for use by more than just the model builder, include a cover page. The cover page should include:
- Company and/or project name
- Description of the model
- Modeler and team contact information
Include a table of contents when the model is sufficiently large to merit it (a good rule of thumb is more than 5 worksheets).
Worksheet Design
Label worksheets by the nature of the analysis (i.e. DCF, LBO, FinStatements, etc…). Tabs should flow logically from left to right. When following the inputs→calculations→output approach, color the worksheet tabs based on this division:

Quick Tips
- Include the company name on the top left of every sheet
- Include the sheet purpose, scenario selected (when relevant), scale, and currency prominently below the company name on each sheet
- Page setup for printing: When a sheet is too long to fit on one page, the top rows containing company name, purpose of the page, currency, and scale should be displayed on top of each page (select “rows to repeat at top” (Page Layout>Page Setup>Sheet)
- Include file path, page number, and date in the footer
How to Integrate Scenario and Sensitivity Analysis
The purpose of building a financial model is to provide actionable insights that were otherwise not readily visible.
Financial models shed light on various critical business decisions:
- How does an acquisition change the financial statements of an acquirer (accretion/dilution)?
- What is a company’s intrinsic value?
- How much should an investor contribute to a project, given specified return requirements and risk tolerances?
Virtually all investment banking models rely on forecasting and assumptions to arrive at the outputs presented to clients.
Because assumptions are by definition uncertain, presenting the financial model’s output in ranges and based on various scenarios and sensitivities is critical.
Scenario analysis can be performed in financial modeling by creating a toggle switch that changes the model assumptions based on the active case (e.g. Base Case, Upside Case, Downside Case), whereas sensitivity analysis can be conducted via building data tables that sensitize the key variables with the most influence on the model output.

")



Very helpful and informative. Thank you for sharing!
Awesome – thanks!
When a cell references another sheet, but also does some calculation, should that cell be green or black? For example, “=BalSheet!H105 * E15”. Here BalSheet!H105 references another sheet’s cell, but also does a calculation by multiplying it by cell E15 (a cell in the current sheet)?
I would color this cell green b/c of the reference to a separate sheet.
Thanks. But I’d rather pull all the details I need in the current sheet prior to any computations. I think it is mentioned as a recommendation up there.
Victor:
Yes, you can absolutely do that and it would be a best practice.
Best,
Jeff
Excellent article.
Very insightful. Thanks to the author and the linkage/disemination platform
very useful content i want 2 pursue my career as an investment banker
Hi Jeff,
Any recommendations for loan repayment schedules (from the loan company perspective)? I currently have have many, ugly curves, and would like to see if there is something more elegant.
Ellie:
This something we cover in our main LBO case study. We do have a simple LBO tutorial at this link: https://www.wallstreetprep.com/knowledge/financial-modeling-quick-lesson-simple-lbo-model/.
Best,
Jeff
“don’t use macros”
Some things can only be done using VBA.
Try protecting your worksheet, whilst simultaneously allowing users to group and ungroup rows / columns. This would be impossible without VBA.
In general, you would not want (or even be allowed) to protect aspects of your model, as your team may need to make changes or edits.
Best,
Jeff
Jeff: Quick question related to adjusting ebitda for leases.. With the FASB change that lists operating lease liabilities as debt, when adjusting ebitda by adding back in rent expense in order to get an apples to apples comparison( i.e EV, including operating lease liabilities/ ebitdar), would you recommend adding in… Read more »
Joe:
I would probably add back all lease costs to capture everything.
Best,
Jeff
Hello, I would like to ask you what was your source of information of costs of Bloomberg Academic, given the fact that we can´t find them in the Bloomberg´s web page??
Humberto:
Where do you see this on this webpage?
Best,
Jeff
Extremely informative article, thank you for posting.
Excellent info. Great to use in tandem with the premium package.
Thanks Casey!